Tokenizers Matter More Than You Think
originally posted on linkedin

A Hands-On Benchmark Across 8 Models and 4 File Types Over the past year, I’ve been dissecting the mechanics behind AI systems, not just how to use them, but how to engineer them. That’s the TD in me. I’ve always been driven to understand the layers beneath the surface: how tools talk to each other, where inefficiencies creep in, and how we can build smarter pipelines from the ground up.
My curiosity drove me to develop a local-first AI evaluation framework that spans tokenizer analysis, prompt-type mapping, semantic matching, and model performance metrics. I have been using it to test models to evaluate their efficiency and performance, in a similar manner to how I approach Animation and VFX pipeline development: methodically, comparatively and always with an eye on scalability.
In this example, I focus on one of the most overlooked but critical components of that system: tokenization.
🔍 What’s in This Test: o200k_base tokenizer (used by GPT-4 Turbo) More aggressive benchmarking structure, including normalized length and runtime File-by-file comparisons across .json, .md, .txt, and .yaml
I ran 8 tokenizers across 8 different text samples, tracking:
Token efficiency (tokens per word) Continued ratio (how often a word is split) Normalized length (how bloated the result is) Tokenization time
🥇 Key Takeaways: 🧠 Top Performer (Compact + Fast): cl100k_base is still the best-balanced tokenizer.
🚀 Surprise Performer: o200k_base (GPT-4 Turbo) came close to matching cl100k_base in speed and slightly improved continued word handling in .md, .txt, and .yaml files. Slightly more tokens overall, but tight performance.
⚠️ Least Efficient: GPT-2, gpt2, r50k_base still produce nearly double the token count of modern tokenizers. Even small prompts bloat quickly. High continued ratios and inflated normalized length across the board.
📦 File Format Impacts: .md files were consistently the most efficient. .yaml and .json were bloated slightly, likely due to formatting structure. .txt files benefited from minimal syntax but exposed tokenizer edge cases (e.g., line breaks and spacing).
📊 Global Efficiency Rankings (Tokens per Word):
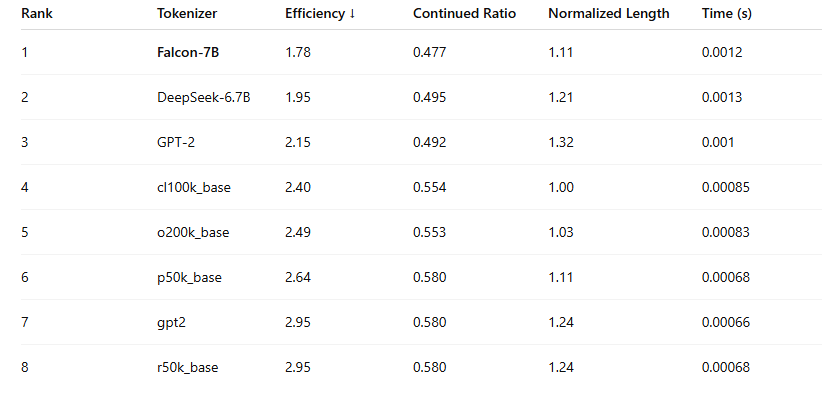 Note: Lower efficiency scores mean fewer tokens per word (better).
Note: Lower efficiency scores mean fewer tokens per word (better).
⚙️ What This Means for You: Whether you are:
Writing optimized prompts Budgeting tokens for API calls Fine-tuning LLMs on structured text
…the tokenizer matters. A lot. Even a 10–15% difference in token count can affect:
Output length Inference cost Generation reliability
In this round, cl100k_base remains the most “production ready” choice. o200k_base is worth watching, especially if you’re migrating to GPT-4 Turbo or managing high-throughput systems.
🎁 If You Made It This Far… This benchmark is just the tip of the iceberg.
I’m building a full-stack AI evaluation system that includes:
🔍 Prompt type classification and coverage 📏 Tokenizer fingerprinting 🧪 Multi-model response evaluation 🧠 Semantic matching tools 🖥️ Local-first infrastructure with Markdown outputs
It’s designed for developers, researchers, and TDs who want more control, more visibility, and better data from their LLM workflows.